上下文工程:不只是写好提示词那么简单
上下文工程:不只是写好提示词那么简单
最近在折腾AI Agent相关的东西,踩了不少坑。说实话,一开始我以为做Agent最难的是模型本身不够聪明,后来发现根本不是——绝大部分时候Agent表现拉胯,是因为你给它塞的信息不对。
就好比你给新同事安排工作,光说"去把这个功能做了"是不够的,得告诉他在哪个项目、用的什么技术栈、之前的人怎么做的、代码放在哪个目录、接口规范是什么......你给的信息越全,他干得越好;你什么都不说,他就只能瞎猜。
大模型也一样。它不是你肚子里的蛔虫,你不说清楚,它就只能靠"猜"。而"怎么把该说的都说清楚"这件事,就是今天要聊的主题——上下文工程(Context Engineering)。
从Karpathy的一个比喻说起
OpenAI的联合创始人Andrej Karpathy之前说过一个很经典的比喻:
LLM就像一种新型的操作系统。LLM本身是CPU,上下文窗口(Context Window)就是RAM(内存)。
这个比喻太精准了。
你想想你的电脑:CPU再快,如果RAM里塞了一堆乱七八糟的东西、有用的数据反而没加载进来,那电脑一样卡成狗。操作系统干了什么?它负责管理什么数据该进内存、什么数据该清出去、哪些进程优先加载。
LLM也是一样。模型本身再强大,如果你往上下文窗口里塞了一堆无关紧要的内容,或者该给的信息没给到,那输出质量必然拉胯。
Karpathy总结了一句话:
上下文工程是"填充上下文窗口的一门微妙的艺术和科学"——在每一步都只放入恰好正确的信息。
说白了,提示词工程(Prompt Engineering)只是上下文工程的一个子集。提示词工程关注的是"怎么写好一句话",而上下文工程关注的是"怎么构建一个动态系统,在合适的时机把合适的信息、工具、知识送到LLM面前"。
这完全不是同一个量级的事情。
LLM应用里的三种上下文
在讲具体怎么做之前,先搞清楚LLM应用里到底有哪些"上下文"。LangChain的博客把它们分成了三大类:
1. 指令(Instructions)
就是你给模型的行为规范。包括:
- 系统提示词(System Prompt)
- Few-shot示例(给几个例子让它知道你想要什么格式)
- 工具描述(告诉模型有哪些工具可以用、怎么用)
- 行为记忆(比如"用户偏好用中文回复")
2. 知识(Knowledge)
就是让模型"知道"一些它训练数据里没有的信息。包括:
- 事实信息(比如你们公司的产品文档)
- 用户记忆(比如"这个用户之前问过什么")
- 业务数据(数据库里的结构化数据)
3. 工具反馈(Tools)
模型调用工具后拿回来的结果。比如:
- 搜索API返回的内容
- 数据库查询的结果
- 代码执行的输出
这三种东西像三条河流,最终都汇入LLM的上下文窗口:
指令(Instructions) ──┐
知识(Knowledge) ──┤──→ 上下文窗口(Context Window)──→ LLM输出
工具反馈(Tools) ──┘
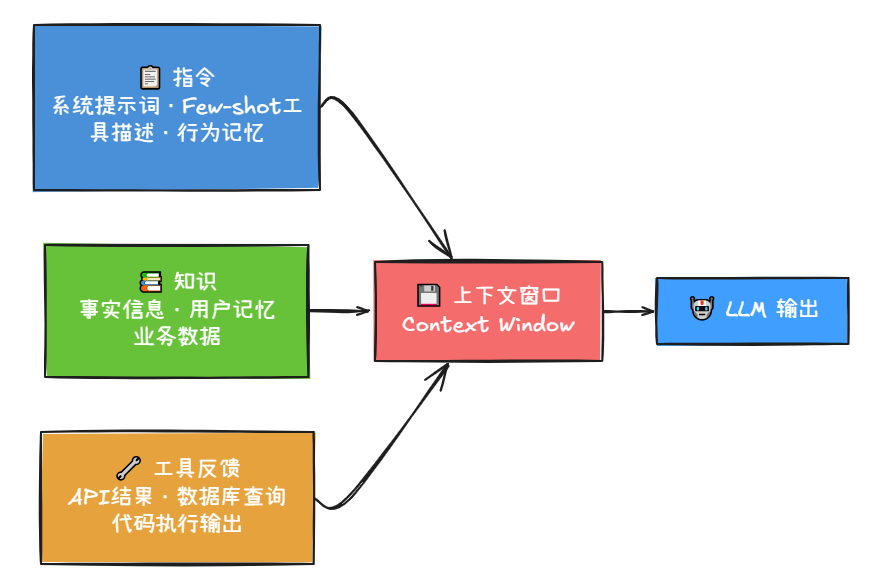
所以上下文工程要管的就是:这三条河里,什么该流进来、什么该挡在外面、什么该先存着以后再说。
读上下文:什么该进来
"读上下文"指的是把信息拉进上下文窗口,帮助模型完成当前任务。
工具调用结果
这是最直接的方式。模型说要查个东西,你让它去调用API,API返回的结果就直接灌进上下文窗口了。
比如你做一个客服Agent,用户问"我的订单到哪了",模型调用物流查询工具,拿到物流信息,然后把结果塞进上下文,再基于这个信息回答用户。
但这里有个坑:工具返回的数据格式特别重要。 一个简洁清晰的错误信息,远比一个巨大的JSON堆要有用得多。就像你跟人沟通一样,怎么说话很重要,怎么把数据呈现给模型也很重要。
检索(RAG)
RAG(Retrieval-Augmented Generation)应该是大家最熟悉的一种上下文工程手段了。
流程大概是:
用户提问 → 问题转成向量(Embedding)→ 去向量数据库里搜索 → 找到相关文档片段 → 注入上下文窗口 → 模型基于这些内容回答
说白了就是开卷考试——你不是让AI凭记忆答题,而是先帮它翻到教材里相关的那一页,然后让它看着内容作答。
我之前写MaxKB那篇文章里聊过这个,MaxKB做的就是帮你把这套"开卷考试"系统搭起来。
不过RAG说起来简单,做好非常难。特别是当你的数据量大了之后,光靠向量搜索根本不够。Windsurf(一个代码编辑器)的工程师Varun说过一段很实在的话:
索引代码不等于上下文检索......我们做了AST解析、按语义边界切分......但是当代码库越来越大,Embedding搜索作为检索手段就不够可靠了......必须结合grep/文件搜索、知识图谱检索、还有重排序(Re-ranking)......
你看,一个做代码编辑器的团队,光"检索"这一件事就搞了这么复杂的组合拳。这就是上下文工程的复杂度。
数据上下文
除了上面两种,还有一些结构化的数据也可以作为上下文灌进去:
- 规划上下文:比如Agent先制定一个执行计划,然后把计划放进上下文,后续步骤都按计划走
- 结构化数据:把数据库查询结果、配置信息等格式化后注入
- 环境上下文:当前时间、用户信息、系统状态等
这些东西看起来琐碎,但往往决定了Agent能不能正常工作。你不说今天是几号,它怎么知道"昨天"是哪天?
写上下文:什么该存起来
"写上下文"是另一个方向——把信息保存到上下文窗口之外,留到以后用。
这事儿听起来有点反直觉:我好不容易把信息放进去了,干嘛又拿出来?
因为上下文窗口是有限的。你塞太多东西进去,要么超出窗口被截断,要么信息太多导致模型"注意力涣散"(没错,这玩意儿有名字,叫"Context Distraction")。
便签本(Scratchpad)
你在工作的时候会怎么做?找张纸记笔记,把关键信息写下来,等需要的时候再看。Agent也可以这么干。
便签本的思路就是:把信息保存到上下文窗口外面,需要的时候再读回来。
Anthropic做的多Agent研究系统就是一个很好的例子。他们的LeadResearcher(主研究员Agent)会先想好研究方案,然后把这个计划保存到Memory里。为什么要保存?因为他们用的Claude模型上下文窗口是200K tokens,一旦超过就会被截断。如果计划只存在上下文里,聊着聊着就被截没了,后面的步骤就完全不知道该干什么了。
LeadResearcher先把方案保存到Memory中,因为一旦上下文窗口超过200,000 tokens就会被截断,而保留方案是至关重要的。
这不就是咱们做笔记的原因吗?怕忘了呗。
实现方式也很灵活——可以是一个工具调用,往文件里写东西;也可以是Agent运行状态(State)里的一个字段,在会话期间持续存在。
记忆(Memory)
便签本解决的是一次会话内的信息保存问题。但有时候Agent需要跨会话记住东西。
比如你跟ChatGPT说过"我喜欢简洁的回答,不要废话",它下次再跟你聊天的时候还能记得这个偏好。这就是跨会话的记忆。
这种记忆分为几种类型:
- 情景记忆:记住之前做过的事(比如"上次用户让我用Java写代码")
- 程序记忆:记住行为规范(比如"回复用中文"、"代码注释用英文")
- 语义记忆:记住事实信息(比如"用户的项目用的是Vue3+SpringBoot")
现在主流的产品都在做这个:
- ChatGPT:有自动生成的长期记忆,可以跨对话记住你的偏好
- Cursor:用规则文件(类似
.cursorrules)保存项目规范 - Windsurf:也有类似的记忆机制
- Claude Code:用
CLAUDE.md文件保存指令和记忆
有些Agent用固定文件来存储记忆——永远拉进上下文,简单粗暴。但如果你存了很多记忆(比如ChatGPT给每个用户存了几百条),怎么挑选出跟当前任务相关的记忆又是一个难题。
Simon Willison(Django的联合创始人)在AI Engineer World's Fair上分享过一个翻车案例:ChatGPT从记忆里取了他的地理位置信息,然后在他要求生成图片的时候意外地注入了进去。这种"不受控的记忆检索"会让用户觉得上下文窗口"不再属于自己"了。
为什么这对做Agent特别重要
聊到这你可能会想:这些东西我知道了,但跟我有什么关系?
如果你只是用ChatGPT聊聊天,那确实关系不大。但如果你要构建AI Agent,那就是天大的事了。
Cognition(做Devin的那家公司)说得非常直接:
"上下文工程......实际上是构建AI Agent的工程师的头号工作。"
Anthropic也说:
"Agent经常进行数百轮的对话交互,需要精心设计上下文管理策略。"
为什么?因为Agent不是一问一答就完了。一个典型的Agent任务可能是这样的:
- 用户说"帮我调研一下XX技术"
- Agent先制定计划
- 然后搜索资料(调用搜索工具)→ 拿到一堆结果
- 分析结果(又调用了几个工具)→ 又拿到一堆结果
- 写总结(基于前面所有的信息)
一个任务下来,几十次工具调用,每次调用的结果都往上下文里塞。如果不做管理,上下文窗口很快就炸了。而且还会有各种问题:
- 上下文污染:模型某一步产生了幻觉,这个错误信息留在了上下文里,后续步骤被带偏
- 上下文分散:塞了太多东西,模型反而找不到重点
- 上下文冲突:不同来源的信息互相矛盾,模型无所适从
所以上下文工程不仅仅是"写好提示词",它是一整套动态系统,需要你在Agent运行的每一步都思考:
- 这一步应该给模型什么信息?
- 哪些信息该留在上下文里,哪些该清出去?
- 哪些信息该先存起来,等需要的时候再拿回来?
- 信息以什么格式呈现最容易被模型理解?
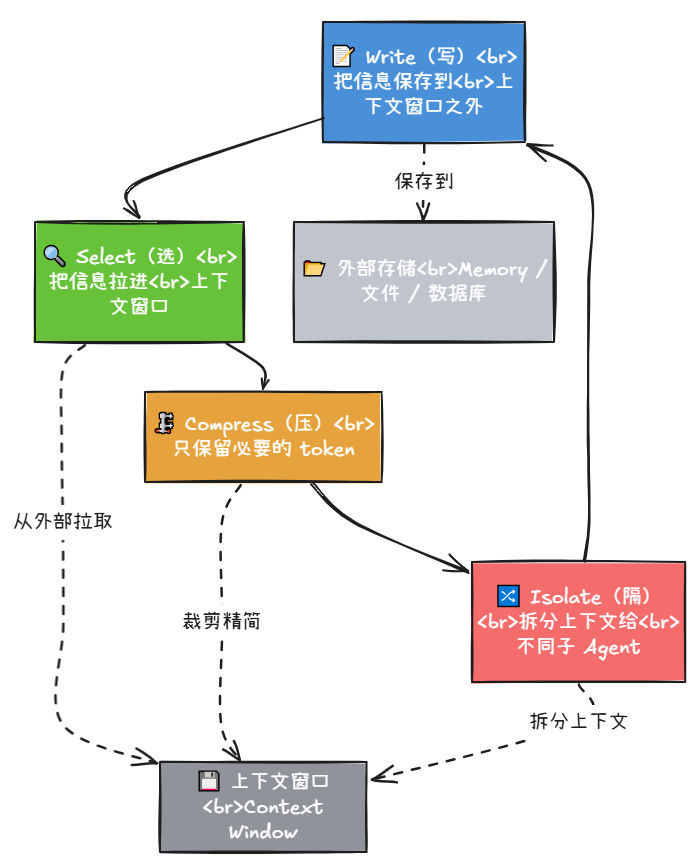
LangChain总结了一套方法论,把上下文工程分成四个动作:
| 动作 | 含义 | 例子 |
|---|---|---|
| Write(写) | 把信息保存到上下文窗口之外 | Agent写笔记、保存记忆 |
| Select(选) | 把信息拉进上下文窗口 | RAG检索、挑选相关记忆、筛选工具 |
| Compress(压) | 只保留必要的token | 对话摘要、裁剪旧消息 |
| Isolate(隔) | 把上下文拆分给不同子Agent | 多Agent协作,各自独立上下文 |
这四个动作不是孤立的,而是组合使用的。比如Agent先Write一个计划到外部存储,后续步骤Select这个计划拉进上下文,中间可能Compress掉一些不重要的工具返回结果,最后把不同子任务Isolate给不同的子Agent去并行处理。
跟提示词工程的区别
最后再明确一下上下文工程和提示词工程的区别,因为这个容易混淆。
提示词工程关注的是:怎么写好一句话(或一段话),让模型给出更好的回答。
上下文工程关注的是:怎么构建一个动态系统,在合适的时机把合适的信息和工具送到模型面前。
打个比方,提示词工程是教你怎么跟人说话——用词准确、逻辑清晰、态度明确。而上下文工程是教你怎么组织一场会议——谁来参加、发什么材料、什么议题先讨论什么后讨论、会议记录怎么存......
提示词工程是上下文工程的子集。你当然需要写好提示词,但光写好提示词远远不够。
就像我之前在Copilot那篇文章里写的:你在项目里建了copilot-instructions.md做约定、写了精准的提示词公式、还建了copilot-context.md做上下文锚点——这三件事加在一起,其实就是在做上下文工程。只是当时不知道这个概念罢了。
总结
上下文工程这事儿说白了就一句话:你给模型的信息决定了模型的输出质量。
模型不是神,它就是个超级学霸——你给它什么参考材料,它就基于什么回答。参考材料对了,回答就靠谱;参考材料错了或者不够,它就只能瞎编。
记住Karpathy的比喻:LLM是CPU,上下文窗口是内存。 你得像操作系统管理内存一样,精心管理上下文窗口里装的东西。
这对做聊天机器人可能不是特别关键,但对构建AI Agent来说,是头号工程问题。
下次你的Agent又给出莫名其妙的回答时,别急着骂模型蠢——先看看你给它塞了什么上下文。