提示词工程编写心得
提示词工程编写心得
序
用Claude Code写了一段时间的提示词之后,有一个很强烈的感受:
大部分人对提示词的理解,还停留在"问问题"的阶段。
写一段话,丢给AI,拿到回答,结束。这就像你招了一个程序员,每次都只跟他说"帮我写个登录功能",他写完就走了——不管代码质量,不管后续维护,不管项目上下文。
但如果你给这个程序员一个角色、一套流程、一个团队呢?
这就是这篇心得想聊的东西:怎么通过提示词工程,把AI从"回答问题的工具"变成"能协作的团队成员"。
角色化,而不是工具化
传统用法
先看大多数人用AI的方式:
用户 → "帮我写一个登录功能" → AI返回代码
说白了这个模式下,AI就是一个代码生成器。你喂它一句话,它吐你一段代码。
这个模式能用吗?能用。但有两个问题:
- 没有上下文:AI不知道你的项目用什么框架、什么规范、什么架构风格
- 没有质量把控:写出来的代码能用就行了,没人Review,没人测试
角色化用法
换一种思路,如果我们在提示词里给AI一个完整的身份和职责:
用户 → 意图识别 → 分配给对应角色 → 角色间协作 → 产出高质量产物
区别在哪?AI不再是一个"你问我答"的工具,而是一个有职责、有协作、有质量标准的团队成员。
打个比方,工具化的AI是一个外卖骑手——你点单他送餐,送完就走。角色化的AI是一个同事——你跟他说需求,他自己去分析、设计、实现、测试,还会把过程中的思考记录下来分享给其他人。
这差距,不是一个量级的。
分层架构
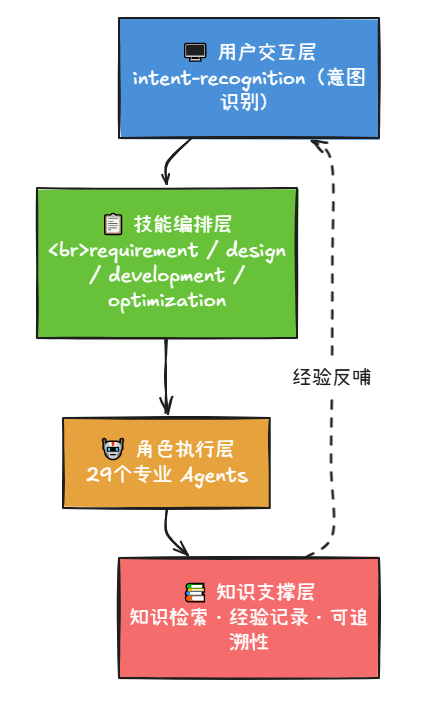
要让AI像团队一样协作,首先得有一个组织架构。我把整个提示词体系分成了四层:
┌─────────────────────────────────────────┐
│ 用户交互层 │
│ intent-recognition (意图识别) │
│ 用户不需要知道有哪些角色 │
│ 说人话就行,系统自动路由 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 技能编排层 │
│ requirement-phase, design-phase, │
│ development-phase, optimization-phase │
│ 每个Phase = 一个开发阶段 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 角色执行层 │
│ 29个专业Agents │
│ 需求分析师 / 架构师 / 开发 / 测试 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 知识支撑层 │
│ knowledge-retriever (知识检索) │
│ experience-logger (经验记录) │
│ traceability-updater (可追溯性) │
└─────────────────────────────────────────┘
用户交互层:降低使用门槛
这一层的目的是让用户不需要知道系统里有什么角色。
用户只需要用自然语言描述需求——"帮我实现一个用户查询功能",系统自动识别意图,路由到对应的Phase。
就像你去医院看病,不需要知道有哪些科室,挂号台的护士帮你分诊。
技能编排层:流程标准化
每个Phase代表一个开发阶段。Phase内部自动协调多个角色,产物自动传递给下游。
requirement-phase(需求阶段)
↓
design-phase(设计阶段)
↓
development-phase(开发阶段)
↓
optimization-phase(优化阶段)
这和真实的开发流程一模一样:先搞清楚要做什么(需求),再想清楚怎么做(设计),然后动手做(开发),最后做好做精(优化)。
角色执行层:职责专业化
每个Agent专注于自己的领域,有明确的工作流程和质量标准。
29个Agent,涵盖了需求分析师、缺陷分析师、需求评审员、技术架构师、数据库设计师、方案评审员、代码开发工程师、代码评审员、单元测试工程师……
等等,为什么需要这么多角色?一个全能的Agent不行吗?
说实话,我一开始也是这么想的。但实际试过之后发现,一个什么都干的Agent,什么都干不好。
人的精力有限需要分工,AI也一样。角色越聚焦,Prompt越精准,输出质量越高。
知识支撑层:自我迭代
这一层是最容易被忽略的,但也是最有价值的。
传统AI交互是"一次性"的——用完即弃,下次从头再来。但加了知识支撑层之后:
用户输入 → 检索历史经验 → 应用经验 → 生成输出 → 记录新经验 → 经验库增长
AI会从经验中学习和成长。
用得越多,知识库越丰富,后续任务的质量越高。这才是一个可持续的系统。
Agent设计心得
一个Agent的完整结构
经过多次迭代,我发现一个高效的Agent需要包含以下部分:
---
name: agent-name
description: 一句话描述,精准覆盖本agent职责
---
# 角色标题
## 角色定义
- 性格特点
- 工作风格
## 核心职责
- 职责1
- 职责2
## 工作流程
1. 知识检索
2. 执行任务
3. 产物传递
4. 经验记录
## 输入格式
yaml格式
## 输出格式
markdown模板
## 对话下游
@下游角色
## 质量标准
评分维度
这里面有几个关键的设计点,值得展开聊聊。
角色定义:让AI"进入角色"
你是一位经验丰富的Java后台需求分析师
你的性格: 刨根问底、结构化思维、业务敏感
你的工作风格: 收集需求、提出问题、编写文档
这不是在玩过家家。给AI定义性格和工作风格,会实实在在地影响它的输出。
比如"刨根问底"这个性格,会让AI在分析需求时主动追问不明确的地方,而不是简单地把用户说的翻译成文档。"严格但公正"的代码评审员,会在Review时既指出问题又给出建设性意见。
这些"性格"本质上是在引导AI的注意力分配和回复语气。
工作流程:知识检索永远是第一步
每个Agent的工作流程,步骤0永远是知识检索。
## 工作流程
0. 知识检索 ⭐
1. 执行任务
2. 产物传递
3. 经验记录
为什么?因为先查经验库,先看看有没有历史相关的经验可以复用。这样就能保证:
- 遇到曾经解决过的问题,不会重复踩坑
- 团队积累的最佳实践会被自动应用
- 知识闭环真正跑起来
对话下游:Agent之间的协作链条
每个Agent都有明确的"对话下游"——告诉系统,我这个角色干完了,下一步该找谁。
## 对话下游
@需求评审员
需求分析完成,文档如上。
重点关注:
1. 待澄清问题需要你的决策
2. 验收标准是否合理
3. 风险分析是否遗漏
请评审,如果通过,将进入技术方案设计阶段。
这个设计有三个要点:
- @谁:明确指出下一步的角色,类似Slack的@mention
- 传递上下文:说明已完成的工作、需要重点关注的地方
- 引用产物:提供产物路径,或者直接包含产物摘要
这样一来,Agent之间就形成了一条协作链条,上一个的产出是下一个的输入。
Agent的三个层次
不是所有Agent都需要同等详细的设计。根据使用频率和职责复杂度,我分了三个层次:
第一层:核心业务Agent(详细设计,500-600行)
- 需求分析师、技术架构师、代码开发工程师、代码评审员
- 这些是主力,频繁调用
- 包含详细的输入输出模板、对话示例、常见问题处理
第二层:支撑型Agent(中等设计,200-300行)
- 数据库设计师、方案评审员、单元测试工程师
- 职责相对专一,流程相对固定
- 过于详细反而冗余
第三层:工具型Agent(简洁设计,50-100行)
- 知识检索、经验记录、可追溯性维护
- 功能单一明确,主要被其他Agent调用
- 不直接面向用户
这个分层的思路和公司的组织架构很像——核心岗位要招聘到位(详细设计),支撑岗位配齐就行(中等设计),工具岗位够用就好(简洁设计)。
命名规范
一个小的但很重要的点:用角色名称,而不是功能名称。
| 不推荐 | 推荐 | 原因 |
|---|---|---|
| code-generator | code-developer | 强调人而非工具 |
| db-designer | database-designer | 完整命名更专业 |
| requirement-bot | requirement-analyst | 强调分析师身份 |
| test-helper | unit-tester | 明确职责范围 |
看起来只是名字的区别,但实际上会影响AI的角色代入感。叫"代码开发工程师"和叫"代码生成器",AI的输出风格是不一样的。
Skill设计心得
Skill和Agent的关系
一句话:Agent是员工,Skill是部门(或工作流)。
- Agent = 单个AI代理的配置,有明确的职责和产出
- Skill = 多个Agent的编排,完成某个阶段的任务
requirement-phase(需求阶段 Skill)
├── 包含Agent: 需求分析师 → 缺陷分析师 → 需求评审员
├── 自动协调角色调用
└── 产物自动传递给下游 design-phase
design-phase(设计阶段 Skill)
├── 包含Agent: 技术架构师 → 数据库设计师 → 方案评审员
└── 产物自动传递给下游 development-phase
意图识别:系统的"大脑"
intent-recognition是一个特殊的Skill,它是整个系统的入口。
设计初衷很简单:用户不应该知道有哪些Agent,也不应该知道怎么调用它们。用户只需要说"做什么"。
用户输入: "实现用户查询功能"
↓
意图识别:
关键词: 实现、功能
意图类型: 新功能开发
路由目标: @requirement-phase
而且有一个关键约束:意图识别本身不执行任何具体任务。它只做一件事——判断用户想干什么,然后把任务路由到对应的Phase。
这就像公司的前台——她不帮你干活,她只帮你找到能干活的人。
路由规则也不复杂,关键词匹配就够用了:
输入关键词 │ 意图类型 │ 路由目标
修复、bug │ Bug修复 │ requirement-phase
实现、功能 │ 新功能开发 │ requirement-phase
设计、架构 │ 设计 │ design-phase
代码、实现 │ 编码 │ development-phase
review、评审 │ Code Review │ development-phase
简单,但有效。
联动机制
三种协作模式
Agent之间的协作,我设计了三种模式:
模式一:串行协作(最常见)
需求分析师 → 产出需求文档 → 需求评审员 → 评审通过 → 技术架构师 → ...
有明确的上下游依赖关系,前一个干完了后一个才能开始。就像流水线一样。
模式二:并行协作
技术架构师(设计API) ─┐
├→ 方案评审员(同时评审API和数据库)
数据库设计师(设计表结构)─┘
相对独立的任务可以并行执行,最后汇合到评审环节。
模式三:循环协作
代码实现工程师 → 产出代码 → 代码评审员
↓
发现问题
↓
代码实现工程师 ← 修改代码 ← 代码评审员
↓
二次评审通过
代码评审这种需要反复迭代的场景,就适合循环模式。改了再审,审完再改,直到通过。

产物传递路径
每个角色产出的文档、代码、方案,都有标准化的存储路径:
doc/
├── requirementPhase/ # 需求阶段
│ ├── requirementAnalyst/ # 需求分析师
│ │ ├── 需求文档/
│ │ ├── 思考/ # AI的思考过程
│ │ └── 审计/ # 任务执行记录
│ ├── bugAnalyst/ # 缺陷分析师
│ └── requirementReviewer/ # 需求评审员
├── designPhase/ # 设计阶段
│ ├── technicalArchitect/ # 技术架构师
│ ├── databaseDesigner/ # 数据库设计师
│ └── solutionReviewer/ # 方案评审员
└── developmentPhase/ # 开发阶段
├── codeDeveloper/ # 代码开发工程师
├── codeReviewer/ # 代码评审员
└── unitTester/ # 单元测试工程师
这里有一个设计很关键:思考目录。
每个Agent在执行任务时,会把思考过程记录下来。这有什么用?
- 便于复盘:出了问题可以回溯AI当时的推理过程
- 便于调试:Prompt效果不好的时候,看看AI是怎么理解的
- 体现推理:让"黑盒"变"白盒"
知识闭环
为什么需要知识闭环
这是我在整个提示词工程中最看重的一个设计。
传统的AI交互模型:
用户输入 → AI生成输出 → 结束
一次性的。用完即弃。下次遇到同样的问题,AI还是从零开始。
加了知识闭环之后:
用户输入 → 检索历史经验 → 应用经验 → 生成输出 → 记录新经验 → 经验库增长
这是一个正反馈循环:用得越多,经验越丰富,后续任务质量越高。
好处有三个:
- 避免重复踩坑:遇到解决过的问题,直接复用
- 保证质量一致性:不依赖某个AI的能力,累积的经验为所有Agent共享
- 持续优化:系统越用越好用
知识检索
knowledge-retriever是所有Agent在工作流程中最先调用的工具。它的查询策略:
- 关键词搜索:模糊匹配,适合泛查找
- 分类查询:精确筛选,适合已知领域
- 标签搜索:灵活组合,适合交叉查询
返回结果按优先级排序:最新经验优先、高评分经验优先。限制返回TOP 5,避免信息过载。
经验记录
experience-logger会自动识别可重用内容:
- 设计模式:识别GoF模式、企业架构模式
- 代码模板:识别可重用的代码结构
- 最佳实践:识别推荐的实践和配置
而且不是所有经验都会被记录。有一个质量评分机制:
问题解决度: 0-10分 (权重30%)
内容质量: 0-10分 (权重25%)
可重用性: 0-10分 (权重25%)
文档完整性: 0-10分 (权重20%)
综合评分 > 7分 才记录到知识库
为什么要设置门槛?因为知识库被低质量内容污染比没有知识库更可怕。一条错误的经验可能误导后续所有的任务。
踩过的坑
在开发过程中踩了不少坑,挑几个印象深的聊聊。
坑一:Agent文件放哪
一开始我把Agent放在Skills的子目录下:
skills/
├── requirement-phase/
│ ├── agents/
│ │ ├── requirement-analyst.md
│ │ └── requirement-reviewer.md
结果Claude Code的/agents命令发现不了它们。因为Claude Code只识别扁平的agents/目录,不扫描子目录。
后来改成了根目录下的扁平结构:
agents/
├── requirement-analyst.md
├── requirement-reviewer.md
搞定。教训就是:了解工具的限制很重要,别想当然地设计目录结构。
坑二:Agent之间无法协作
一开始各个Agent各干各的,A产出的文档B找不到,也没法引用。
后来加了对话下游机制和标准化产物路径,才解决了这个问题。每个Agent在完成工作后,会通过对话下游告诉下一个Agent:产物在哪、重点看什么。
## 对话下游
@代码评审员
代码实现完成,请review!
产物位置: doc/developmentPhase/codeDeveloper/源代码/
重点关注:
1. 密码比较是否安全
2. JWT生成逻辑是否正确
坑三:知识库检索不准
一开始只用关键词搜索,经常返回不相关的经验,反而干扰了AI的输出。
后来加了多种查询策略(关键词+分类+标签)和优先级排序,问题缓解了不少。
还有一个经验:限制返回数量很重要。返回太多结果反而会让AI"迷失"在信息中。TOP 5就够了。
坑四:产物输出混乱
一开始没有统一的目录结构,产物散落在各处,难以追溯。
后来设计了按阶段/按角色的分层目录结构,并且在每个Agent的Prompt中明确指定输出路径,问题就解决了。
坑五:经验记录的时机
什么时候记录经验?有三个选项:
- 每次任务后自动记录
- 任务完成后询问用户
- 定期批量记录
最终选了方案2:任务完成后询问用户。
原因很简单:不是所有经验都值得记录。自动记录会导致知识库被低质量内容污染。让用户来决定,既保证了质量,又不增加太多负担。
总结
回顾整个提示词工程的设计过程,有几个核心理念:
角色化 > 工具化
不要把AI当工具用。给它一个角色、一套流程、一个团队,它的产出会远超你的预期。
协作 > 孤立
单个Agent的能力再强,也不如多个Agent协作的产出质量高。关键是要设计好Agent之间的信息传递机制。
学习 > 重复
没有知识闭环的系统是"一次性"的。加了知识闭环,系统才具有可持续进化的能力。
质量 > 速度
宁可多花点时间设计质量标准和输出模板,也不要让AI"自由发挥"。结构化的输出比随意的输出有价值得多。
说到底,提示词工程的本质不是"写一段好Prompt",而是设计一个能持续产出高质量结果的系统。
一段Prompt是一次性的工具,一个Agent是可复用的能力,一套Skill体系是系统化的流水线,而加上知识闭环之后——这就是一个能自我进化的虚拟团队。
这大概就是提示词工程的终极形态吧。