当你在和AI说话的时候,它在想什么?
当你在和AI说话的时候,它在想什么?
前两天在群里看到一位同事吐槽:"我让Copilot帮我改个接口,结果它给我写了个跟项目完全不同风格的代码,还得自己改半天,还不如我自己写。"
旁边另一位同事也附和:"我让它帮我排查个bug,就说'我的代码跑不起来',它给我回了一大堆通用排查步骤,没有一个有用的。"
这种场景太熟悉了。
说白了,大家用AI编程助手的时候,心里都默认了一个前提——它应该能"看到"我的整个项目,理解我的所有意图。
但现实是残酷的:它既看不到你的整个项目,也猜不透你脑子里在想什么。
于是乎,问题来了:当你在和AI说话的时候,它到底能"看到"什么?
搞清楚这个问题,你的AI使用体验会从一个"不太聪明的助手"直接升级到"还挺靠谱的搭档"。
什么是"上下文"
你跟一个新来的同事说"帮我改一下那个东西",他会一脸懵——因为他不知道"那个东西"是哪个东西。
AI也一样。它需要足够的信息才能给出有用的回答,这些信息就叫上下文(Context)。
当你在IDE里打开Copilot的对话框,敲下一行"帮我写个接口"的时候,AI能"看到"的东西大概有这么几类:
- 当前文件内容:你现在正在编辑的那个文件,AI是能看到的
- 默认提示词:比如你在
.github/copilot-instructions.md里写的那些约定,每次都会自动加载 - 聊天记录:同一个对话窗口里你们之前聊过的内容
- 项目结构:文件目录、部分关联文件(但注意,是"部分")
- 你主动粘贴/引用的代码片段
用生活场景来打个比方:
你去医院看病。医生能获取的信息就是你的病历本(当前文件)、你之前在这家医院的就诊记录(聊天记录)、你主诉的症状(你的输入)。但如果你什么都不说就往那一坐,医生再厉害也只能给你开个常规检查。
AI的上下文就是它的"视野范围",超出这个范围的东西,它真的一无所知。
Token——AI的"记忆单位"
聊上下文就不得不聊一个核心概念:Token。
你可能经常看到这个词,但一直没搞明白它到底是什么。简单来说:
Token是AI处理文本的最小单位,你可以把它理解成AI的"记忆单元"。
我们写代码用的是字符,但AI不直接读字符,它先把文本"切碎"成一堆Token,然后再理解和处理。
举几个实际的例子感受一下:
| 文本内容 | 大约Token数 |
|---|---|
Hello, World! | 3-4 个 |
你好世界 | 6-8 个(中文消耗更多Token) |
| 一个50行的函数 | 200-400 个 |
| 一整个Java文件(500行) | 2000-4000 个 |
| 一个中等项目所有代码 | 几十万甚至上百万个 |
注意到没有?中文消耗的Token比英文多。因为大部分大模型的分词器是按英文优化的,一个中文字可能要拆成2-3个Token。
所以当你发现用英文提问AI回答更"聪明"的时候,不一定是它在装,可能真的是Token太吃紧了。
上下文窗口——AI的"工作台面"
每个AI模型都有一个**上下文窗口(Context Window)**的限制,说白了就是它能一次性处理的Token上限。
打个比方:
AI的上下文窗口就像你的工作台面,就这么大,东西多了就放不下。你的办公桌能同时摊开几本书、几份文件?摊太多了,重要的东西反而被埋在下面找不到。
目前主流编程助手的上下文窗口大小:
- Copilot(GPT-4系列):约128K Token,换算下来大约96,000个词
- Claude系列:200K Token
- 国产大模型:128K ~ 256K不等
96,000个词听着很多对吧?但你想想,一个正经项目的代码量——随便一个SpringBoot项目,光依赖的源码就上百万Token了。你的业务代码加上配置文件、数据库脚本、前端代码……早就爆了。
所以AI不可能一次性"看完"你整个项目的所有代码,这是物理限制,不是它不想。
AI到底是怎么处理你的请求的
知道了上下文和Token的概念,我们来看看当你按下回车键的那一刻,到底发生了什么:
你输入问题
↓
IDE(如VSCode、IDEA)
↓
Copilot后端开始收集上下文
├── 当前文件内容
├── 关联文件(通过import、调用关系推断)
├── 项目结构(目录树)
├── copilot-instructions.md(如果有)
├── 聊天记录
└── 你引用/粘贴的额外代码
↓
把收集到的上下文 + 你的问题 组装成一个"大文本"
↓
发送给AI模型
↓
模型在上下文窗口内理解并生成回答
↓
返回结果到IDE
用Mermaid时序图来看,整个流程更清晰:
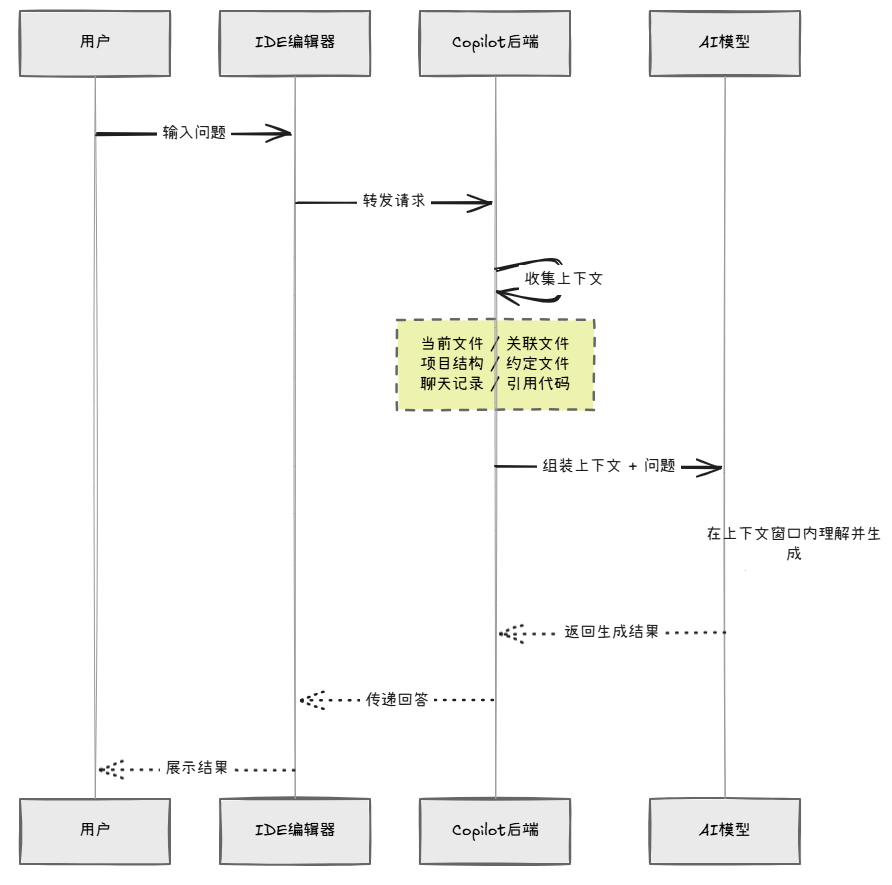
关键环节是**"收集上下文"这一步**。
Copilot(以及其他AI编程助手)并不是傻乎乎地把所有代码都塞进去——它也没法这么做,上下文窗口装不下。它会用一套策略来挑选最相关的信息:
- 当前文件:权重最高,基本都会加载
- 打开的标签页:你IDE里同时打开的其他文件
- 代码引用链:通过import、函数调用等关系找到的关联文件
- 语义搜索:用你的问题去项目里搜相关代码片段
注意这个"挑选"过程。它意味着:如果相关信息没有被"选上",AI就完全不知道它的存在。
这就是为什么有时候AI给出的答案会让你拍桌子——不是它笨,是它压根没看到。
两个最常见也最致命的误区
误区一:AI能"看到"整个项目
真相:AI大部分时候是在"搜索"和"猜测",不是在"阅读"。
很多人以为打开Copilot聊天框的那一刻,AI就已经把整个项目代码都过了一遍。这个想法很美好,但完全不是事实。
实际情况是:Copilot会根据你的问题去项目里搜索相关代码片段,然后把搜到的片段塞进上下文里。搜索结果好不好,直接决定了AI回答的质量。
这就像你在公司里问一个同事问题,他不会先把公司所有文档都读一遍再回答你,而是先想想"这个问题大概跟哪些文档有关",然后去翻那几个文档。
所以如果你的问题太模糊,搜索出来的结果就不对路,AI自然就答非所问了。
误区二:给的上下文越多越好
真相:无关信息会"淹没"关键信息,反而降低回答质量。
有些同学知道上下文的重要性之后,就开始疯狂地往对话里塞东西——整个文件、整个目录的代码全贴进去,觉得"信息越全,AI越聪明"。
但事实恰恰相反。
想象一下你在考场上做阅读理解。卷子上就一篇短文,你能精准找到答案。但如果在短文前面又给你塞了十篇无关的文章,你的注意力就会被分散,找答案反而更慢更不准。
AI也一样。上下文窗口就那么大,塞了一堆无关代码进去,真正重要的信息反而被"稀释"了。学术上有个词叫"注意力稀释",说白了就是——东西太多,AI抓不住重点了。
正确做法是:只给AI跟当前任务直接相关的信息,宁精勿滥。
实战:不同上下文质量,完全不同的结果
光说理论没感觉,来看三个真实案例。
案例一:创建一个API接口
低质量上下文:
帮我写一个获取用户列表的接口
AI的处境:不知道你的项目用什么框架,不知道返回格式规范,不知道数据库表结构,不知道你习惯用MyBatis还是JPA……
结果:给你一个通用的SpringBoot接口,返回格式大概率不符合你项目的统一封装,字段命名风格可能也不对。
高质量上下文:
[项目信息] Java8 + SpringBoot + MyBatis-Plus
[返回格式] 统一使用Result<T>封装,参考Result.java
[分页要求] 使用Page<T>分页,参考PageResult.java
[表结构] 用户表sys_user,字段:id, username, email, status, create_time
[命名规范] 驼峰命名,Mapper继承MpBaseDao
帮我写一个获取用户列表的分页查询接口,支持按username模糊搜索,按status过滤
结果:生成的代码直接能跑——Controller、Service、Mapper分层清晰,分页参数校验完整,返回格式跟你项目一模一样。
差距在哪? 第二种告诉了AI框架选型、返回格式、表结构、命名规范——这些都是它无法"猜"出来的信息。
案例二:重构一段代码
低质量上下文:
// 直接丢一段代码过去
public void processOrder(Order order) {
// 50行处理逻辑...
}
帮我重构这段代码
AI不知道这段代码在项目里是什么角色、有什么性能要求、调用链是什么样的。结果可能给你一个"看起来很优雅但完全脱离项目实际"的重构方案。
高质量上下文:
[项目背景] 订单处理模块,当前这段代码耦合了验证、计算和持久化逻辑
[性能要求] 这段代码是高频调用路径,QPS约500,重构后不能引入额外性能损耗
[技术栈] Java8 + Spring + MyBatis-Plus
[重构目标]
1. 拆分职责,符合单一职责原则
2. 保持对外接口不变(processOrder方法签名不动)
3. 方便后续扩展新的订单类型
[约束] 不要引入新的外部依赖,只用项目中已有的工具类
以下是待重构的代码:
```java
public void processOrder(Order order) {
// 50行处理逻辑...
}
结果:AI会给你一个务实的重构方案——策略模式处理不同订单类型、校验逻辑独立抽取、不引入新依赖,而且保持接口兼容。
**差距在哪?** 第二种明确了重构的目标、约束和边界,AI不会"过度设计"也不会"脱离实际"。
### 案例三:排查Bug
**低质量上下文:**
我的代码跑不起来了,报错了,帮我看看
AI连你的代码都没看到,报什么错也不知道,用什么环境也不清楚。它能做什么?给你列一堆"常见报错排查步骤",等于什么都没说。
**高质量上下文:**
[环境] Java8 + SpringBoot 2.7 + MySQL 8.0 [报错信息] org.springframework.dao.DataIntegrityViolationException:
Error updating database. Cause: java.sql.SQLIntegrityConstraintViolationException:
Duplicate entry 'ORDER_20250420_001' for key 'uk_order_no'
[相关代码]
@Transactional
public void createOrder(OrderDTO dto) {
Order order = new Order();
order.setOrderNo(generateOrderNo()); // 生成订单号
orderMapper.insert(order);
}
[复现条件] 并发场景下,多个线程同时创建订单时偶现 [已尝试] 我确认数据库里没有重复数据,generateOrderNo()方法有加时间戳
请帮我分析这个唯一键冲突的原因并给出修复方案
结果:AI直接定位问题——`generateOrderNo()`在高并发下可能生成重复的订单号,时间戳精度不够导致碰撞。修复方案:用雪花算法或者数据库序列,或者在`generateOrderNo()`里加分布式锁。
**差距在哪?** 第二种提供了报错信息、相关代码、复现条件、已尝试的操作。这些信息让AI能**精准定位**问题,而不是瞎猜。
## 一个好用的提问模板
总结上面的案例,可以提炼出一个实用的提问模板:
[场景定位] 你在做什么 [技术栈] 用了什么框架/版本 [具体问题/需求] 你要AI帮你做什么 [关键约束] 不可协商的条件(性能、兼容性、规范等) [相关代码/错误信息] 直接相关的代码片段或报错堆栈 [输出要求] 你期望AI怎么回答(分层输出?只给方案不改代码?)
不是每次提问都要把所有元素填满,但至少要包含**场景定位**和**具体问题**。其他元素根据实际情况补充——信息越精准,回答越靠谱。
## 写在最后
回到开头那个问题:当你在和AI说话的时候,它在想什么?
答案是——**它在想你能让它"看到"的那些东西**。
它看不到你脑子里对"那个东西"的定义,看不到你没打开的文件,看不到你项目里没被搜索到的代码,更看不到你没说出口的需求和约束。
**你和AI之间的沟通质量,完全取决于你给它多少有效的上下文。**
下次AI给你一个让你想砸键盘的回答时,先别急着骂它笨。想想看:你给它的信息,够不够它做出一个聪明的回答?
> 记住:**AI不是你的同事,它不会主动问"你说的是哪个接口?"、"你的报错信息是什么?"。它只会基于你给的信息尽可能地去回答——给多少,它就理解多少。**
搞懂上下文机制之后,你会发现AI编程助手从一个"有时好用有时不好用的工具",变成一个"只要你沟通到位就一直好用的搭档"。