Token到底是个什么鬼:给程序员的AI计费扫盲
Token到底是个什么鬼:给程序员的AI计费扫盲
某天,你打开Claude CLI的账单页面,或者随手翻了翻OpenAI的用量统计,看到这么一行:
Input tokens: 52,318
Output tokens: 12,847
Cost: $0.38
你盯着这个页面看了三秒钟,脑子里冒出三个问号:Token是啥?5万多个?我干啥了就花了0.38刀?
so┭┮﹏┭┮,这篇文章就是来回答这些问题的。
Token到底是个什么
先说结论:Token是AI阅读和生成文本的最小单位。
我们人类读文字,是一个字一个字(或者一个词一个词)地看。但AI不一样,它不认识"字"这个概念。它会把一段文本先拆成一个个小片段,这些小片段就叫Token。
这个过程有个专门的名字——分词(Tokenization),流程大概是这样:
原始文本 → [Tokenizer分词器] → Token序列

举个实际的例子。
英文文本
"Hello, World!"
经过分词器处理后,大概是3-4个Token:
["Hello", ",", " World", "!"]
你看,一个常见的问候语,AI眼里就是4个小碎片。
中文文本
"你好,世界!"
看起来比英文短对吧?但经过分词器处理后,可能是6-8个Token:
["你", "好", ",", "世", "界", "!"]
没错,中文几乎每个字都单独算一个Token。这就意味着,表达同样的意思,中文消耗的Token数量通常比英文多。
这不是歧视中文,而是因为目前主流的大语言模型(GPT、Claude这些)的训练语料以英文为主,分词器对英文的压缩效率更高。一个英文单词经常就是一个Token,但一个中文字可能就需要一个Token甚至更多。
代码文本
一个50行左右的Java方法,大概消耗200-400个Token。一个完整的Controller文件(300行),可能就是2000-3000个Token。
一个好记的经验法则
- 1个Token ≈ 4个英文字符,或者说≈ 0.75个英文单词
- 1个Token ≈ 1-2个中文字
- 1000个Token大概就是750个英文单词,或者300-500个中文字
不用精确到个位数,有个量级概念就行。
上下文窗口:AI的"内存"
知道了Token是什么,接下来聊一个和Token紧密绑定的概念——上下文窗口(Context Window)。
你可以把上下文窗口理解为AI的"工作记忆",就像你电脑的内存条。内存有多大,AI一次性能"记住"的内容就有多少。
每个模型都有自己的上下文窗口上限:
| 模型 | 上下文窗口 | 大概能装多少东西 |
|---|---|---|
| GPT-4 | 128K tokens | 约96,000个英文单词,一部中等长度的小说 |
| GPT-4o | 128K tokens | 同上 |
| Claude 3.5 Sonnet | 200K tokens | 约150,000个英文单词,一部长篇小说 |
| Claude 3 Opus | 200K tokens | 同上 |
| GPT-3.5 | 16K tokens | 约12,000个英文单词,一篇长文 |
| DeepSeek-V3 | 128K tokens | 约96,000个英文单词 |
128K tokens听起来很多对吧?但关键在于——上下文窗口里装的不只是你当前这一条消息。
一次对话里,以下所有东西都会占上下文窗口的空间:
- 系统提示词(System Prompt):比如"你是一个专业的Java开发助手"这种设定
- 你发的每一条消息
- AI回复的每一条消息
- 你粘贴的代码/文件内容
- 工具调用和返回结果(如果用了MCP、Function Calling等)
这些东西全部叠在一起,就这么一个池子。用满了怎么办?AI就开始"失忆"了——最早的消息会被截断或者遗忘。
这就像你在看一本很长的技术书,看到第10章的时候,第1章的内容已经记不太清了。AI也一样。
Token怎么影响你的日常工作
理解了Token和上下文窗口,很多日常使用AI时的"玄学"现象就说得通了。
为什么聊着聊着AI就变笨了
你跟AI来来回回聊了一个小时,让它帮你重构代码、写接口、调Bug。一开始它回答得又快又准,但聊到后面,你发现它开始"胡说八道"了——明明之前的逻辑是对的,现在又开始瞎改。
原因:上下文窗口满了。早期的对话被截断,AI已经不记得你最初说的需求和约束了。它只能根据剩下的最近的几轮对话来猜你要什么。
解法:开一个新的对话窗口,把关键上下文重新整理后发给它。
为什么粘贴整个文件是浪费
有时候为了让AI理解你的代码结构,你直接把一个2000行的Service实现类整个粘贴进去。
这一个文件可能就吃掉5000-10000个Token。加上之前的对话历史、系统提示词,你一下就用掉了上下文窗口的好几十分之一。
而且AI并不会因为你贴了更多代码就回答得更好。它真正需要的可能只是其中某几个方法。
解法:只贴相关的代码片段,而不是整个文件。或者像在之前的文章里说的,用锚点文件的方式让AI按需读取。
为什么Copilot/Claude有时候会"忘记"你说过的话
你告诉AI"用驼峰命名",它前几轮都记得,后面突然又开始用下划线了。
原因:还是上下文窗口的问题。包含你命名约定要求的那条消息已经被截断了。
解法:把关键约束写在System Prompt或者copilot-instructions.md里,这样每轮对话都会自动加载,不怕被截断。
计费模式:你的Token值多少钱
搞清楚Token是什么之后,终于可以聊钱了。
目前主流的AI工具/平台,计费模式主要分两种。
按Token计费
代表选手:Claude API、OpenAI API、各类CLI工具。
计算公式很简单:
总费用 = 输入Token数 × 输入单价 + 输出Token数 × 输出单价
注意,输入和输出的单价不一样,而且输出通常比输入贵好几倍。
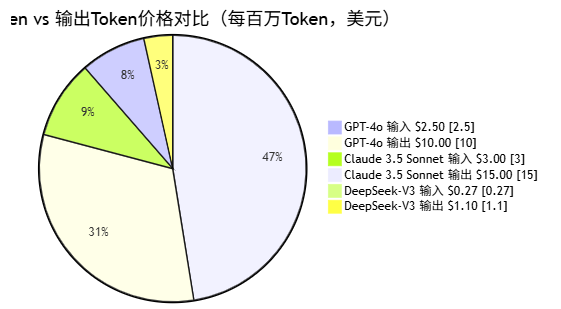
以2025年的价格为例(仅供参考,实际价格以官网为准):
| 模型 | 输入价格(每百万Token) | 输出价格(每百万Token) |
|---|---|---|
| GPT-4o | $2.50 | $10.00 |
| Claude 3.5 Sonnet | $3.00 | $15.00 |
| DeepSeek-V3 | $0.27 | $1.10 |
为什么输出比输入贵?因为生成文本(输出)比理解文本(输入)需要更多的计算资源。输入是"读",输出是"写"加"思考",后者更费脑。
这种模式的特点:
- 用多少算多少,很公平
- 对于短查询特别划算(问个正则表达式,可能就花0.001刀)
- 但如果你天天让AI帮你读整本代码库,费用会积少成多
按订阅/请求计费
代表选手:GitHub Copilot($10/月或$19/月)、Cursor Pro($20/月)。
这种模式你交一个固定的月费,然后用多少Token都行(当然会有fair use限制)。
听起来很划算?但要注意,平台后台依然在按Token计费,只不过这个费用由平台替你承担了。他们赌的就是:大多数用户的平均用量,低于他们收的月费。
这种模式的特点:
- 费用可预测,每月固定支出
- 重度用户薅到就是赚到
- 轻度用户可能反而不划算(一个月就用几次,10刀的月费和直接买Token比反而贵了)
两种模式怎么选
简单粗暴的建议:
| 你的使用场景 | 推荐模式 |
|---|---|
| 每天都在用AI写代码 | 订阅制(Copilot/Cursor Pro) |
| 偶尔用用,或者只是做自动化脚本 | 按Token计费(API) |
| 需要处理大量文本(代码审查、文档分析) | 看情况,量特别大的话API可能更可控 |
| 团队统一采购 | 订阅制,管理方便 |
说实话,如果你是全职写代码的程序员,Copilot的月费是最省心的选择。一个月10-20刀,比你每天花时间算Token费用要划算得多。
省Token的实操技巧
不管你是按Token付费还是用订阅制,省Token都是好习惯。按Token付费的省钱,用订阅的能让AI的回答更准确(因为上下文窗口不会被垃圾信息占满)。
1. 提示词精简,去掉废话
❌ "你好,我想请问一下,能不能帮我写一个用于用户注册的正则表达式?需要验证邮箱格式的那种,谢谢!"
✅ "写一个邮箱格式验证的正则表达式"
两句话要的结果完全一样,但Token消耗差了好几倍。AI不需要你的礼貌用语,它只需要明确的指令。
2. 只给相关代码,别贴整个文件
❌ [粘贴整个UserService.java,2000行]
"帮我看看register方法有什么问题"
✅ [只粘贴register方法,30行]
"这段注册方法有什么问题"
效果一样,Token消耗差了几十倍。
3. 用代码引用代替粘贴
如果你的工具支持(比如Copilot、Cursor),直接用@文件名或者#行号引用代码,让AI自己去读,而不是手动粘贴。这样工具会自动按需读取,不会一股脑全塞进上下文。
4. 上下文太长就开新对话
当你感觉到AI的回答质量开始下降,或者对话已经进行了很长时间,别犹豫,直接开一个新的对话窗口。把关键信息重新整理后告诉AI,比在一个已经"臃肿"的对话里继续纠缠要高效得多。
5. 英文提示词更省Token
同一个意思,英文表达通常比中文少用30%-50%的Token。如果你的英文还行,可以试试用英文写提示词,让AI用中文回复。
❌ "请帮我分析一下这段代码的性能问题,并给出优化建议" (约25个Token)
✅ "Analyze performance issues and suggest optimizations" (约8个Token)
当然这个技巧在实际使用中看个人,如果英文表达不够精确反而影响效果,那就别勉强。
程序员的Token心算手册
最后,给各位开发者一个实用的Token心算参考表。不需要精确计算,有个直觉就够了。
| 对象 | 大概Token数 |
|---|---|
| 1行Java代码 | 10-20个Token |
| 1行Python代码 | 8-15个Token |
| 1行SQL | 15-25个Token |
| 1页A4文本(约500字) | 500-800个Token |
| 一个典型的CRUD接口方法 | 50-100个Token |
| 一个完整Controller类(200行) | 2,000-3,000个Token |
| 一个Service实现类(500行) | 5,000-8,000个Token |
| 一次典型的API请求(提示词+上下文) | 2,000-10,000个Token |
| 一次代码审查(带上下文) | 10,000-50,000个Token |
| 整个项目扫描(100个文件) | 200,000+个Token |
几个关键数字记一下:
- 200K tokens:Claude的上下文上限。100个Java文件就能塞满,更别提还带着对话历史了。想用AI"读整个项目"?醒醒,装不下。
- 128K tokens:GPT-4的上限。大约一个中等规模的模块(30-50个文件)加对话历史就满了。
- 1个Token ≈ 0.001个人民币(按GPT-4o的输入价格算)。一个复杂任务跑下来可能也就几毛钱。
写在最后
Token这个东西,说白了就是AI世界的"流量计"。你跟AI说的每句话、贴的每段代码、AI回你的每个字,都在这个流量计上跑。
理解了Token,你就理解了:
- 为什么AI有时候会"忘记"你说过的话——上下文窗口满了
- 为什么账单上会有这么多Token——中文本身就费Token,代码也不便宜
- 为什么要精简提示词——省Token就是省钱,也是给AI减负
- 为什么不同模型收费差这么多——上下文窗口大小、输出质量、推理能力都是定价因素
以后再看到账单上的Token数,应该不会慌了吧。
如果这篇文章对你有帮助,那这2000多个Token就算没白花。