Spring AI Agent应用架构设计
Spring AI Agent 应用架构设计
序
自从开始用Claude Code做数字分身之后,一直在思考一个问题:
这些Prompt驱动的AI能力,能不能用Java工程化的方式落地?
毕竟在企业里,Python再灵活也不好管理。Java才是大部分公司的基础设施——Spring Boot、MyBatis、MySQL、Redis这些老伙计都在。
恰好Spring AI在2025年出了1.0正式版,提供了ChatClient、Tool Callback、Chat Memory这些开箱即用的能力。于是就想试试,用Spring那一套东西,能不能搭出一个像模像样的AI Agent平台。
于是就做了一个基于Spring AI的多模块Agent平台。
本篇就来聊聊这个过程中,架构怎么搭的、思路怎么走的、踩了哪些坑。
架构总览
先看整体结构。项目拆了6个模块,每个模块职责清晰:
physical-ai/
├── agent-app/ # 应用入口(Controller、配置、启动)
├── agent-common/ # 公共层(实体、DTO、枚举、异常)
├── agent-core/ # 核心引擎(编排器、路由、对话管理、提示词)
├── agent-infra/ # 基础设施(数据库、Redis、WebSocket、SSE)
├── agent-llm/ # LLM网关(Spring AI封装、记忆管理)
└── agent-tools/ # 工具框架(注解、注册中心、外部系统集成)
模块之间的依赖关系:
agent-app(入口)
├── agent-core(核心引擎)
│ ├── agent-llm(LLM网关)
│ │ ├── agent-tools(工具)
│ │ └── agent-infra(基础设施)
│ └── agent-infra
└── agent-common(公共)
为什么要拆这么多模块?说实话一开始我是想一个模块搞定的。但做着做着发现,LLM调用、工具注册、对话管理这三块的关注点完全不同——
LLM层关注的是模型选择、Token管理、流式输出;工具层关注的是注解扫描、外部API调用、危险操作确认;核心层关注的是意图路由、上下文编排。
混在一起就是一锅粥,拆开之后每个模块都可以独立迭代。
核心链路
先不看细节,把整个系统的核心链路画出来:
用户请求
│
▼
ChatController(接收请求)
│
▼
AgentOrchestrator(编排器,系统核心)
│
├── 1. AgentRouter.detectAgent() → 意图识别,匹配Agent
├── 2. SystemPromptBuilder.build() → 构建系统提示词
├── 3. DialogManager.loadContext() → 加载对话上下文
├── 4. LlmGateway.chat() → 调用LLM
│ │
│ ├── 传入 ToolCallbacks(工具)
│ ├── 传入 历史消息(记忆)
│ └── 传入 SystemPrompt(角色设定)
│ │
│ └── Spring AI 自动处理 ReAct 循环
│ LLM → 需要工具?→ 调用工具 → 返回结果 → LLM继续 → ...
│
├── 5. DialogManager.appendMessage() → 保存响应
└── 6. DialogManager.saveContext() → 保存上下文
│
▼
返回ChatResponse(同步)或 Flux<ChatResponse>(流式)
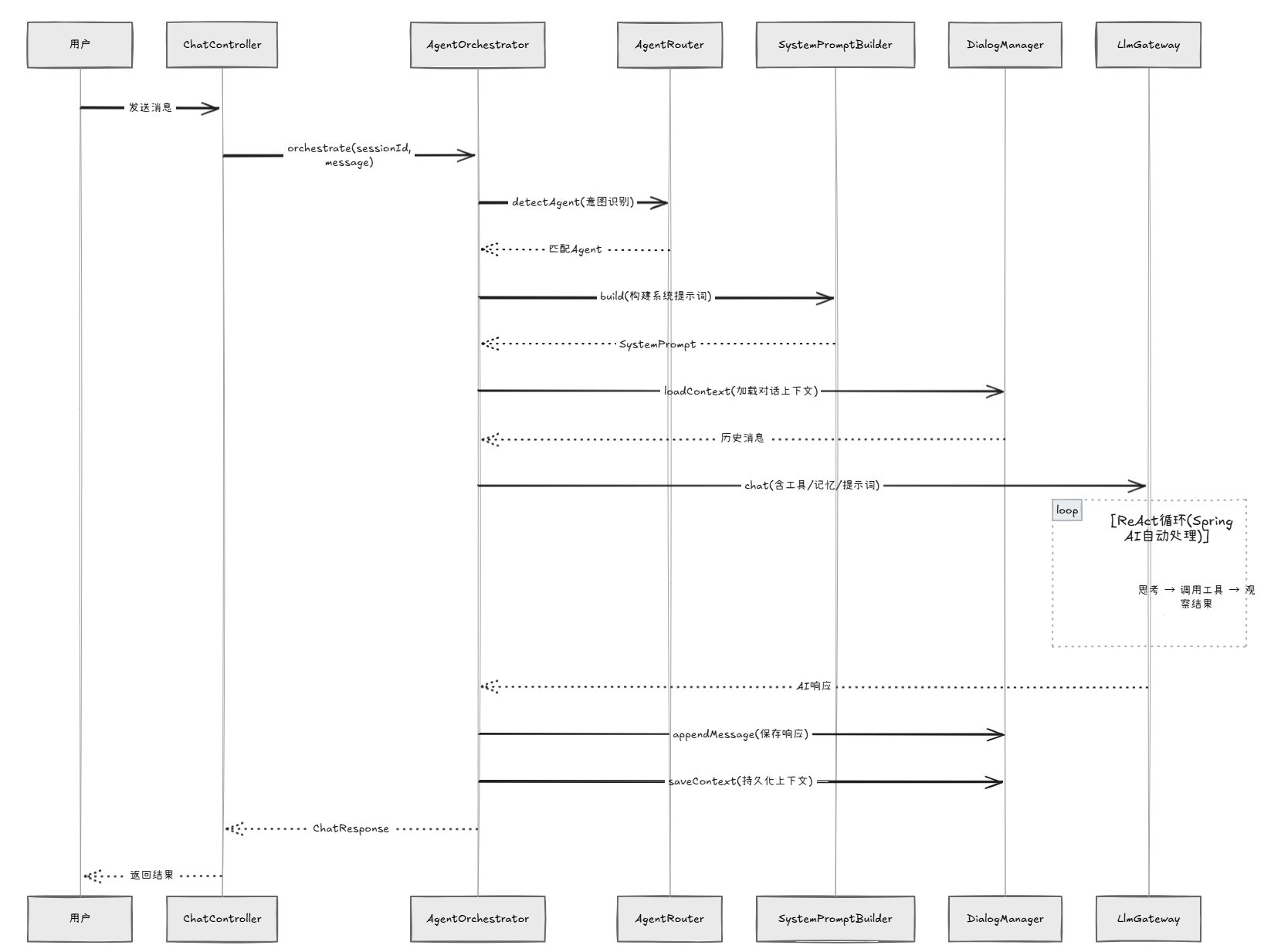
这就是整个系统最核心的一条链路。下面逐个展开。
Agent路由:意图识别
设计思路
用户发一条消息过来,系统怎么知道该用哪个Agent来处理?
最简单的做法是一个Agent打天下。但实际业务中,不同场景需要不同的角色设定和工具集。比如一个客服Agent和一个数据分析Agent,它们的人格、能力、响应格式完全不同。
所以需要一个路由层——根据用户消息的内容,自动匹配最合适的Agent。
路由策略
路由的策略设计得比较务实:
function detectAgent(userMessage, currentAgentId):
// 策略1: 会话已绑定Agent → 直接复用
if currentAgentId != null:
return registry.getAgent(currentAgentId)
// 策略2: 只有一个Agent → 没得选
if agents.size() == 1:
return agents.get(0)
// 策略3: 调用LLM做意图识别
candidates = formatAgentList(agents)
prompt = "以下是可用的AI助手列表:\n" + candidates
+ "\n\n用户消息:" + userMessage
+ "\n\n请选择最合适的助手,只返回ID"
detectedId = llmGateway.detectIntent(prompt)
return registry.getAgent(detectedId)
三层策略,优先级从高到低:
- 会话绑定:同一个会话内,一旦绑定了某个Agent,后续消息都走这个Agent。这很合理——你和一个人聊天不会每句话换一个人。
- 唯一Agent:如果系统只配了一个Agent,废话不多说直接用。
- LLM识别:真正需要智能路由的场景。把所有Agent的描述告诉LLM,让它来选。
Agent注册中心
Agent定义存在数据库里,启动时加载到内存缓存:
@PostConstruct
function init():
definitions = repository.findAllActive()
for def in definitions:
agentMap.put(def.agentId, def)
if def.isDefault:
defaultAgentId = def.agentId
增删改Agent之后,调用refreshCache()刷新。简单有效。
ReAct编排:系统的灵魂
什么是ReAct
ReAct(Reasoning + Acting)是Agent的核心模式。简单说就是:
循环 {
思考:分析当前情况,决定下一步做什么
行动:如果需要调用工具,就调用工具
观察:获取工具返回的结果
继续:基于新信息继续思考
} 直到任务完成
Spring AI的ReAct实现
在项目中,ReAct循环不是自己实现的——Spring AI帮我们做了。
关键在于ChatClient配合ToolCallback。当你把工具注册到ChatClient后,Spring AI会自动处理整个ReAct循环:
ChatClient.prompt()
.system(systemPrompt) // 角色设定
.messages(historyMessages) // 历史记忆
.user(userMessage) // 当前消息
.toolCallbacks(toolCallbacks) // 可用工具
.call() // 触发调用
// Spring AI内部自动执行:
// 1. 把消息发给LLM
// 2. LLM返回"我需要调用某个工具"
// 3. Spring AI自动调用对应工具
// 4. 把工具结果追加到消息中
// 5. 再次发给LLM
// 6. 重复直到LLM给出最终回答
这就是为什么DefaultLlmGateway的代码看起来这么简单——复杂的ReAct循环Spring AI全包了。
编排器的职责
既然Spring AI处理了ReAct循环,那AgentOrchestrator做什么?
它负责的是ReAct之外的事情:
orchestrate(sessionId, userMessage):
// ReAct之前的准备
agent = agentRouter.detectAgent(...) // 路由
context = dialogManager.loadContext(...) // 加载记忆
prompt = systemPromptBuilder.build(...) // 构建提示词
dialogManager.appendMessage(USER, ...) // 记录用户消息
// ReAct本身(Spring AI处理)
response = llmGateway.chat(userMessage, context)
// ReAct之后的收尾
dialogManager.appendMessage(ASSISTANT, ...) // 记录AI响应
dialogManager.saveContext(...) // 持久化上下文
return response
编排器是"事前准备 + 事后收尾"的角色,ReAct核心循环交给Spring AI。
工具系统:最难设计的部分
说实话,整个项目中工具系统的设计花了我最多时间。
难在哪
工具系统有几个特别棘手的问题:
1. 怎么让LLM知道有哪些工具可用?
Spring AI提供了@Tool注解,标记在方法上,Spring AI会自动把方法签名、参数描述、返回值告诉LLM。LLM在需要调用工具时,会返回一个结构化的工具调用请求。
2. 怎么统一管理工具?
需要一个注册中心,自动扫描所有@Tool方法。这里用了Spring的BeanPostProcessor:
ToolRegistry implements BeanPostProcessor:
// 扫描所有Bean
postProcessAfterInitialization(bean, beanName):
if bean有@Tool注解的方法:
callbacks = ToolCallbacks.from(bean) // Spring AI自动转换
toolCallbacks.addAll(callbacks)
Spring容器启动时,自动扫描、自动注册。新增工具只需要写一个带@Tool注解的方法,零配置。
3. 怎么处理危险操作?
这是最复杂的。创建用户、删除用户这些操作,不能AI说删就删。必须有一个确认流程。
危险操作确认机制
设计了一个Token确认机制:
时序:
用户: "帮我创建一个新用户,账号test001"
│
▼
LLM: "我需要调用cmsAddUser工具"
│
▼
cmsAddUser (标记了@DangerousOperation):
│
├── 不是直接调用API
├── 而是生成一个确认令牌
├── 把操作参数暂存到 PendingActionStore
└── 返回: { needsConfirmation: true, token: "abc123", summary: "将在CMS系统中创建用户: test001" }
│
▼
LLM: 收到确认请求,告诉用户 "这个操作需要您确认"
│
▼
用户: "确认执行"
│
▼
LLM: "我需要调用cmsConfirmAction工具,传入token=abc123"
│
▼
cmsConfirmAction:
│
├── 从 PendingActionStore 取出暂存的参数
├── 真正调用API执行操作
└── 返回执行结果
实现上用了装饰器模式——ToolRegistry扫描到标记了@DangerousOperation的方法时,自动用DangerousOperationToolCallback包装一层,在工具描述后面追加确认提示:
原始描述: "【创建新用户】在CMS系统中创建一个新用户账号"
追加后: "【创建新用户】在CMS系统中创建一个新用户账号
请直接调用此工具,系统会自动处理用户确认流程,不要自行用文字向用户确认。"
这样LLM就知道:这个工具可以直接调用,系统会自动处理确认流程。
外部系统集成框架
CMS只是示例。设计了一个通用的外部系统集成框架,接入新系统只需要:
- 实现
BusinessSystemIntegration接口(定义API操作) - 继承
AbstractExternalMcpTools(模板方法,处理认证、调用、确认) - 在
@Tool方法中构建参数,调用基类方法
AbstractExternalMcpTools 提供的模板方法:
├── execute() 普通查询
├── executeWithQuery() URL参数查询
├── executeDirect() 直接传body
├── executeDangerous() 危险操作(生成确认令牌)
├── executeDangerousDirect() 危险操作(直接body)
└── confirmAction() 确认执行
子类不用关心Token管理、API调用、错误处理这些通用逻辑。
工具响应截断
还有一个容易被忽略但很重要的点:工具返回的结果可能很长。
如果查了一个1000条的用户列表直接丢给LLM,上下文窗口瞬间炸了。所以加了一个截断机制:
truncateToolResponse(body):
if body.length > 4000:
return body.substring(0, 4000) + "[响应已截断...]"
return body
4000字符是经验值,既保留了足够的信息,又不至于撑爆上下文。
对话记忆:二级缓存
设计思路
对话记忆的核心问题是:怎么让AI记住之前聊过什么?
最简单的方案是每次把历史消息全部加载出来塞给LLM。但在生产环境中,这个方案有两个问题:
- 数据库压力大:每轮对话都要查一次数据库
- 延迟高:数据库查询 + 序列化需要时间
所以设计了MySQL + Redis二级缓存:
┌──────────────────────────────────────────────┐
│ PersistentChatMemory │
│ │
│ get(conversationId): │
│ 1. 先查Redis缓存 │
│ ├── 命中 → 直接返回 │
│ └── 未命中 → 查MySQL │
│ ├── 有数据 → 写入Redis │
│ └── 无数据 → 空记忆 │
│ │
│ add(conversationId, messages): │
│ 1. 写入MySQL(持久化) │
│ 2. 更新Redis缓存 │
│ │
│ clear(conversationId): │
│ 1. 删除Redis缓存 │
│ 2. 删除MySQL数据 │
│ │
└──────────────────────────────────────────────┘
Redis缓存设置了120分钟的TTL,活跃会话走Redis,冷会话走MySQL。
实现方式
直接实现Spring AI的ChatMemory接口:
PersistentChatMemory implements ChatMemory:
add(conversationId, messages):
// 写MySQL
for message in messages:
messageRepository.save(toEntity(message))
// 刷Redis
memoryStore.saveMessages(conversationId, allMessages)
get(conversationId):
// 先Redis后MySQL
cached = memoryStore.loadMessages(conversationId)
if cached != null: return cached
messages = messageRepository.findBySessionId(conversationId)
memoryStore.saveMessages(conversationId, messages)
return messages
Spring AI会自动在ReAct循环中使用这个ChatMemory,不需要手动管理。
系统提示词:不只是角色设定
响应格式模板
系统提示词不只是"你是一个XXX助手"这种角色设定。还有一个很实用的功能——响应格式模板。
不同场景下,AI回答的格式可能需要不同。比如工具调用结果需要表格展示,闲聊场景需要自然语言。
设计了一个ResponseTemplateRegistry,模板存在数据库中,按作用域(SCENE/TOOL)和Agent ID分组:
SystemPromptBuilder.build(customPrompt, agentId):
basePrompt = customPrompt 或 默认提示词
// 查询该Agent绑定的模板
toolTemplates = registry.getTemplates("TOOL", agentId)
sceneTemplates = registry.getTemplates("SCENE", agentId)
if 有模板:
return basePrompt + "\n\n===== 响应格式规范 =====\n"
+ toolTemplates + sceneTemplates
return basePrompt
模板可以动态增删改,不用改代码,不用重启。
多租户:Advisor拦截
多租户是很多企业系统的刚需。在LLM调用链中注入租户信息,用的是Spring AI的Advisor机制:
TenantContextAdvisor implements CallAdvisor:
adviseCall(request, chain):
tenantId = TenantContext.getTenantId() // 从ThreadLocal获取
userId = TenantContext.getUserId()
if tenantId != null:
// 把租户信息注入到请求上下文中
request = request.mutate()
.context(tenantId, userId)
.build()
return chain.nextCall(request)
Advisor就像Servlet的Filter,在LLM调用前后做拦截。这样租户信息就能贯穿整个调用链。
踩过的坑
坑一:Spring AI 1.0的数值类型问题
这个坑折磨了我很久。
Spring AI 1.0的MethodToolCallback在处理数值类型参数时,内部走的是BigDecimal转换。当LLM传null或空字符串时,直接抛NumberFormatException,整个工具调用链崩溃。
解决方案很朴素:所有参数都用String类型。
// 错误写法
@Tool(description = "查询用户")
public String queryUser(@ToolParam(description = "页码") int pageNum)
// 正确写法
@Tool(description = "查询用户")
public String queryUser(@ToolParam(description = "页码") String pageNum)
方法内部自行解析。丑是丑了点,但稳定。
坑二:流式响应的收集
流式聊天时,LLM是一块一块返回内容的。但对话历史需要保存完整的响应,不能只保存最后一个chunk。
解决方案是用StringBuilder在流式过程中累积完整响应:
orchestrateStream(sessionId, userMessage):
StringBuilder fullResponse = new StringBuilder()
return llmGateway.chatStream(userMessage, context)
.doOnNext(chunk -> fullResponse.append(chunk.content))
.doOnComplete(() -> {
// 流结束后保存完整响应
dialogManager.appendMessage(ASSISTANT, fullResponse.toString())
dialogManager.saveContext(...)
})
坑三:危险操作确认的死循环
一开始的设计中,确认流程有两个入口:危险操作工具和确认工具都能触发执行。结果LLM有时候会绕过确认工具,直接再次调用危险操作工具,导致创建两个PendingAction——死循环。
解决方案是职责分离:
executeDangerous():只负责创建PendingAction,不执行confirmAction():只负责执行PendingAction,不创建
两个方法各管各的,LLM不会搞混。
坑四:Token传递问题
外部系统的认证Token从HTTP请求头来,存在ThreadLocal里。但Spring AI的ReAct循环可能在不同线程执行工具调用,ThreadLocal就丢了。
解决方案是在ExternalAuthFilter中把Token存入ThreadLocal,在工具调用时从ExternalAuthContext取。Spring AI的工具调用是在主线程执行的,所以目前没有问题。但如果未来改成异步执行,需要换成InheritableThreadLocal或其他方案。
架构设计总结
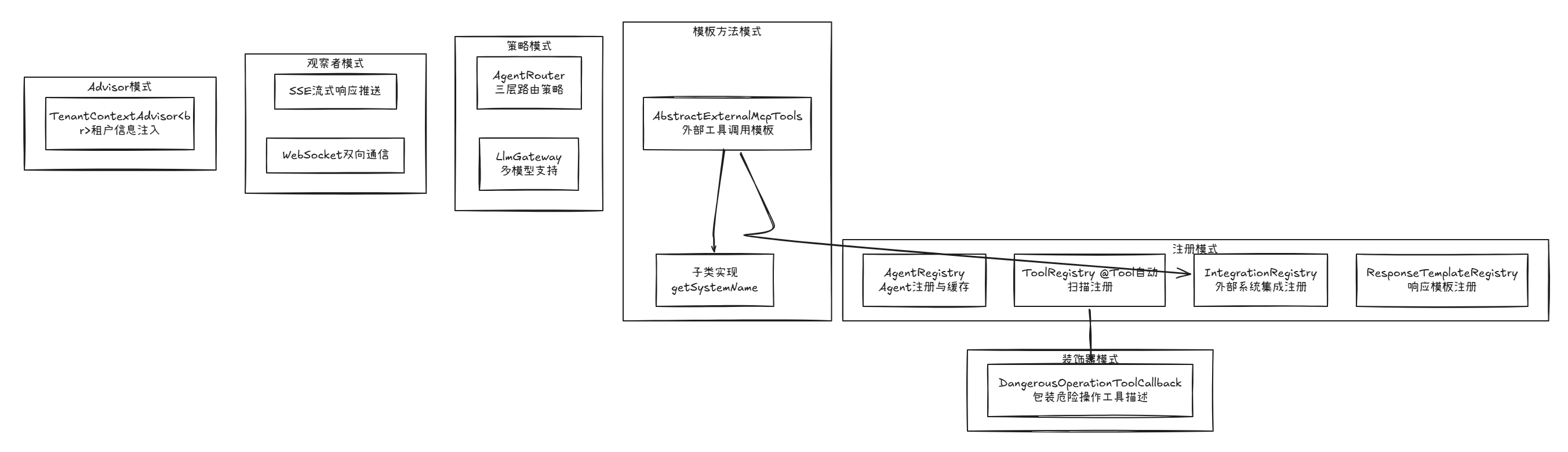
把整个系统的设计模式串一下:
┌──────────────────────────────────────────────────────────────┐
│ 设计模式一览 │
├──────────────────────────────────────────────────────────────┤
│ │
│ Registry模式: │
│ AgentRegistry → Agent注册与缓存 │
│ ToolRegistry → @Tool自动扫描与注册 │
│ IntegrationRegistry → 外部系统集成注册 │
│ ResponseTemplateRegistry → 响应模板注册 │
│ │
│ Template Method模式: │
│ AbstractExternalMcpTools → 外部工具调用的模板方法 │
│ 子类只需实现getSystemName() + 调用基类方法 │
│ │
│ Decorator模式: │
│ DangerousOperationToolCallback → 包装危险操作的工具描述 │
│ │
│ Strategy模式: │
│ AgentRouter的三层路由策略 → 绑定/唯一/LLM识别 │
│ LlmGateway的多模型支持 → Anthropic/OpenAI可切换 │
│ │
│ Observer模式: │
│ SSE → 流式响应推送 │
│ WebSocket → 双向实时通信 │
│ │
│ Advisor模式: │
│ TenantContextAdvisor → 租户信息注入 │
│ │
└──────────────────────────────────────────────────────────────┘
最后
回过头看这个项目,最大的感触是:Spring AI 1.0已经把AI应用开发的基础设施做得相当完善了。
ChatClient封装了LLM调用,ToolCallback封装了工具注册,ChatMemory封装了对话记忆。ReAct循环更是开箱即用。
真正需要花心思设计的,是业务层面的事情:
- 怎么路由到不同的Agent
- 怎么管理工具的生命周期
- 怎么处理危险操作的确认流程
- 怎么做对话记忆的持久化和缓存
- 怎么做多租户隔离
这些Spring AI不管,得自己设计。
所以Spring AI做的是"基础设施",我们要做的是"业务架构"。两者结合起来,才能出一个能用的Agent平台。
说到底,AI应用开发和传统的应用开发没什么本质区别——分层、解耦、设计模式这些老套路依然适用。只不过以前调用的是数据库,现在调用的是大模型。
接口变了,架构思想没变。