Canal:当你的两个系统需要数据同步时
Canal:当你的两个系统需要数据同步时
前段时间碰到一个棘手的需求:公司有个软件分1.0和2.0两个版本,因为历史遗留问题,两个版本的功能、数据结构差异巨大。但是用户要求可以随意在两个版本之间切换,而且切换时数据得是同步的。
换句话说,1.0版本的数据变更要实时同步到2.0,反之亦然。
两个截然不同的系统,要做到数据实时同步,怎么搞?
一开始想过在业务层做双写,但想想就觉得不靠谱——每次增删改都要写两套逻辑,而且一旦有一方写入失败,数据就不一致了。
后来选了Canal,用数据通道的方式,监听1.0数据库的变更,自定义转换逻辑后写入2.0的表。效果还不错,所以来聊聊这个东西。
Canal是什么
Canal 是阿里巴巴开源的一个数据同步工具,纯Java写的。
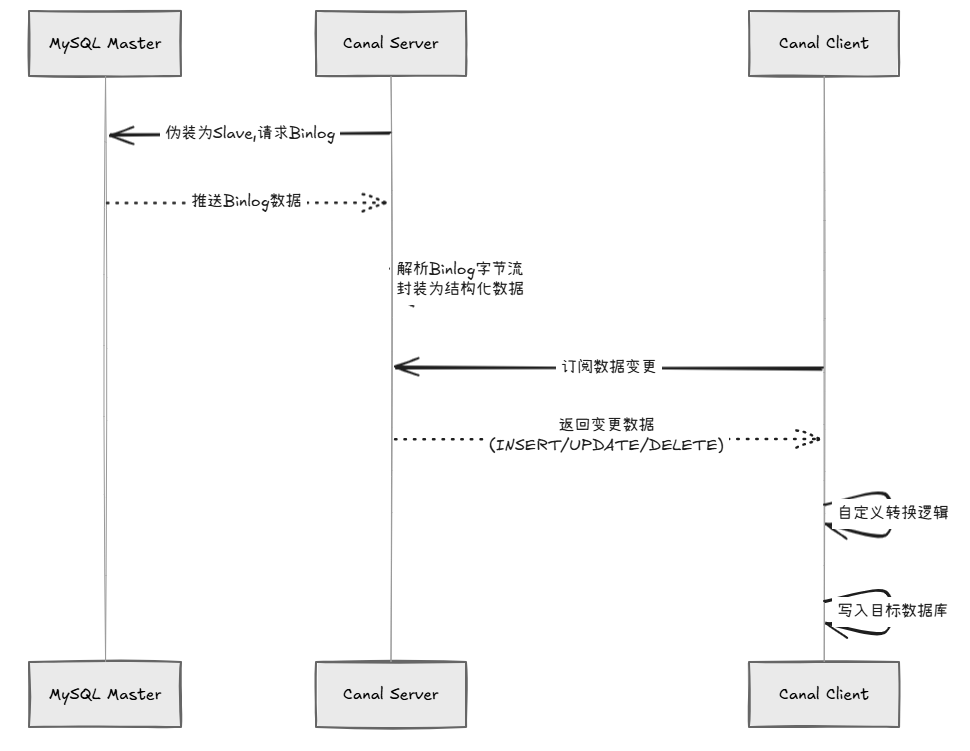
它干的事情用一句话概括就是:伪装成MySQL的从库,监听主库的数据变更,然后把这些变更推给你。
原理其实跟MySQL的主从复制一样。正常情况下,MySQL的主从复制是Master把Binlog发给Slave,Slave重放Binlog达到数据同步。Canal就是扮演了这个Slave的角色:
- Canal伪装成MySQL Slave,向Master请求Binlog
- Master收到请求后,把Binlog推给Canal
- Canal解析Binlog(原始是字节流),封装成好用的数据结构
- 你拿到变更数据,爱怎么处理怎么处理
简单来说,Canal就是一座架在数据库和你的业务之间的数据桥梁。 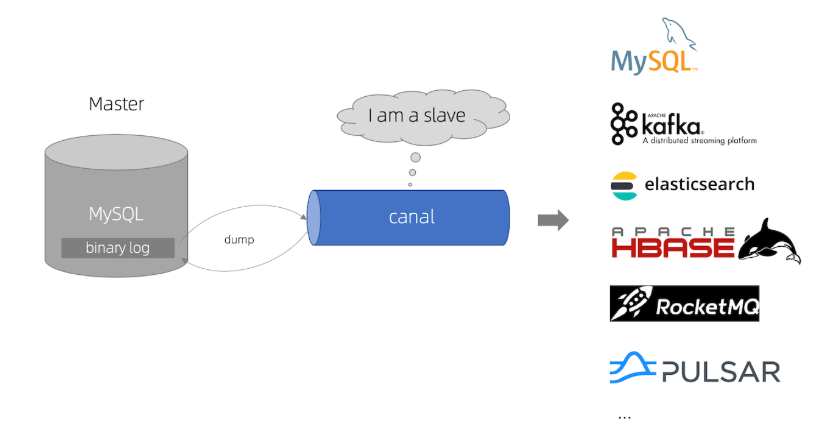
安装部署
Canal的部署分两部分:MySQL配置和Canal Server部署。
MySQL配置
首先得让MySQL开启Binlog。修改my.cnf:
[mysqld]
log-bin=mysql-bin
binlog-format=ROW # 必须是ROW模式,Canal只认这个
server_id=1 # 唯一的Server ID
然后给Canal创建一个专用的MySQL账号:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
就这三步,MySQL那边就搞定了。
Canal Server
从 Canal GitHub Releases 下载压缩包
解压:
tar -zxvf canal.deployer-1.1.x.tar.gz -C /usr/local/canal改配置
conf/example/instance.properties:
# MySQL地址
canal.instance.master.address=127.0.0.1:3306
# 刚才创建的canal账号
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
# 要监听哪些库表,默认全部
canal.instance.filter.regex=.*\\..*
- 启动(注意不要用root账号):
sh bin/startup.sh
启动后默认监听11111端口。
有什么组件
一个完整的Canal体系包含这些:
- Canal Server:核心服务,负责连接MySQL、拉取Binlog、解析和存储
- Canal Client:你写的消费端,连接Server订阅数据变更
- Canal Adapter:官方提供的通用客户端,可以直接同步到ES、HBase、Kafka等目标
- Canal Admin:Web管理界面,集中管理多个Server和Instance
不过我实际用的时候,只用了Server + 自己写的Client。因为我的场景需要自定义数据转换逻辑,Adapter不够灵活。
怎么用:手写一个客户端
回到开头说的那个场景:监听1.0数据变更,自定义转换后写入2.0。
引入依赖:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
核心代码:
public class SimpleCanalClient {
private final CanalConnector connector;
private final ScheduledExecutorService executorService;
private final AtomicBoolean running = new AtomicBoolean(false);
private final CanalProperties canalProperties;
@Autowired
public SimpleCanalClient(CanalProperties canalProperties) {
this.canalProperties = canalProperties;
CanalProperties.Server server = canalProperties.getServer();
this.connector = CanalConnectors.newSingleConnector(
new InetSocketAddress(server.getHost(), server.getPort()),
server.getDestination(),
server.getUsername(),
server.getPassword()
);
this.executorService = Executors.newSingleThreadScheduledExecutor();
}
/**
* 启动客户端
*/
@PostConstruct
public void start() {
connector.connect();
log.info("Canal客户端已启动,监听目的地: {}", JSONUtil.toJsonStr(canalProperties));
connector.subscribe(".*\\..*");
connector.rollback();
// 每3秒处理一批数据
executorService.scheduleWithFixedDelay(this::process, 3, 3, TimeUnit.SECONDS);
running.set(true);
}
/**
* 处理Canal消息
*/
@Retryable(value = {Exception.class}, maxAttempts = 3, backoff = @Backoff(delay = 2000))
private void process() {
if (!running.get()) return;
try {
Message message = connector.get(canalProperties.getClient().getBatchSize());
List<CanalEntry.Entry> entries = message.getEntries();
if (entries != null && !entries.isEmpty()) {
for (CanalEntry.Entry entry : entries) {
if (entry.getEntryType() == CanalEntry.EntryType.ROWDATA) {
try {
// 表名
String tableName = entry.getHeader().getTableName();
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
// 变更前的数据
List<CanalEntry.Column> before = rowData.getBeforeColumnsList();
// 变更后的数据
List<CanalEntry.Column> after = rowData.getAfterColumnsList();
// 在这里写你的转换和同步逻辑
}
} catch (Exception e) {
log.error("处理Canal中实体:{},消息失败", entry.getHeader().getTableName());
}
}
}
}
} catch (Exception e) {
log.error("处理Canal消息失败", e);
throw e;
} finally {
// 回滚,确保消息不丢失
connector.rollback();
}
}
/**
* 停止客户端
*/
@PreDestroy
public void stop() {
running.set(false);
executorService.shutdown();
connector.disconnect();
log.info("Canal客户端已停止");
}
}
阿里的otter框架已经把Canal的数据获取和封装极度简化了。拿到CanalEntry.Entry之后,通过getRowDatasList()就能获取到数据变更前后的每一个字段的差异。
你需要做的就是在注释处写上自己的转换逻辑——拿到变更数据,转成2.0系统的格式,然后插入到2.0的表里。
踩过的坑
用下来之后,整理了一些常见问题:
连接不上MySQL
最常见的问题。检查清单:
- 网络通不通
- MySQL的canal用户权限对不对
server_id配置了没- Binlog格式是不是ROW
消费不到数据
instance.properties里的filter.regex配没配对- 看
logs/example/example.log有没有报错 - 目标表是不是发生了DML操作(INSERT/UPDATE/DELETE),DDL默认不捕获
同步延迟高
这个要看具体原因:
- 网络带宽够不够
- Canal Server和Client所在机器的负载高不高
- 如果数据量大,可以先停Client让Server追平Binlog,再启动Client消费
- 如果用了MQ,确保MQ的吞吐量跟得上
消息堆积
Canal Server内部有一个内存环状缓冲区(RingBuffer),工作流程是:
- Server从MySQL拉取Binlog
- 解析后存入RingBuffer
- Client从RingBuffer获取数据
- Client返回ACK确认后,Server才能覆盖这部分空间

所以关键就是Client的消费速率要跟得上Server拉取Binlog的速率。一旦Client消费太慢,RingBuffer满了,新的Binlog就处理不了了。
总结
Canal解决的核心问题就是:在不侵入业务代码的前提下,实现数据库之间的数据同步。
你不需要改原来的业务代码,不需要做双写,只需要部署一个Canal Server,然后写一个Client订阅数据变更就够了。
当然,它也有局限性——只能监听MySQL的Binlog,对其他数据库无能为力。而且同步的实时性取决于你的消费速率,数据量特别大的时候还是会有延迟。
但对于像我这种"两个不同系统之间做数据同步"的场景来说,Canal确实是一个非常实用且轻量的选型方案。